So you want to use force control to control the orientation of your end-effector, eh? What a noble endeavour. I, too, wished to control the orientation of the end-effector. While the journey was long and arduous, the resulting code is short and quick to implement. All of the code for reproducing the results shown here is up on my GitHub and in the ABR Control repo.
Introduction
There are numerous resources that introduce the topic of orientation control, so I’m not going to do a full rehash here. I will link to resources that I found helpful, but a quick google search will pull up many useful references on the basics.
When describing the orientation of the end-effector there are three different primary methods used: Euler angles, rotation matrices, and quaternions. The Euler angles 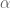

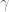
Most modern robotics control is done using quaternions because they do not have singularities, and it is straight forward to convert them to other representations. Fun fact: Quaternion trajectories also interpolate nicely, where Euler angles and rotation matrices do not, so they are used in computer graphics to generate a trajectory for an object to follow in orientation space.
While you won’t need a full understanding of quaternions to use the orientation control code, it definitely helps if anything goes wrong. If you are looking to learn about or brush up on quaternions, or even if you’re not but you haven’t seen this resource, you should definitely check out these interactive videos by Grant Sanderson and Ben Eater. They have done an incredible job developing modules to give people an intuition into how quaternions work, and I can’t recommend their work enough. There’s also a non-interactive video version that covers the same material.
In control literature, angular velocity and acceleration are denoted 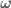

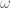
How to generate task-space angular forces
So, if you recall a post long ago on Jacobians, our task-space Jacobian has 6 rows:
![\left[ \begin{array}{c} \dot{\textbf{x}} \\ \pmb{\omega} \end{array} \right] = \textbf{J}(\textbf{q}) \; \dot{\textbf{q}}](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7B%5Ctextbf%7Bx%7D%7D+%5C%5C+%5Cpmb%7B%5Comega%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Ctextbf%7BJ%7D%28%5Ctextbf%7Bq%7D%29+%5C%3B+%5Cdot%7B%5Ctextbf%7Bq%7D%7D&bg=ffffff&fg=555555&s=0&c=20201002)
In position control, where we’re only concerned about the 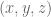
Now that we’re interested in orientation control, however, we will need to learn up (and thank you to Yitao Ding for clarifying this point in comments on the original version of this post). The Jacobian for the orientation describes the rotational velocities around each axis
To generate our task-space angular forces we will have to generate an orientation angle error signal of the appropriate form. To do that, first we’re going to have to get and be able to manipulate the orientation representation of the end-effector and our target.
Transforming orientation between representations
We can get the current end-effector orientation in rotation matrix form quickly, using the transformation matrices for the robot. To get the target end-effector orientation in the examples below we’ll use the VREP remote API, which returns Euler angles.
It’s important to note that Euler angles can come in 12 different formats. You have to know what kind of Euler angles you’re dealing with (e.g. rotate around X then Y then Z, or rotate around X then Y then X, etc) for all of this to work properly. It should be well documented somewhere, for example the VREP API page tells us that it will return angles corresponding to x, y, and then z rotations.
The axes of rotation can be static (extrinsic rotations) or rotating (intrinsic rotations). NOTE: The VREP page says that they rotate around an absolute frame of reference, which I take to mean static, but I believe that’s a typo on their page. If you calculate the orientation of the end-effector of the UR5 using transform matrices, and then convert it to Euler angles with axes='rxyz' you get a match with the displayed Euler angles, but not with axes='sxyz'.
Now we’re going to have to be able to transform between Euler angles, rotation matrices, and quaternions. There are well established methods for doing this, and a bunch of people have coded things up to do it efficiently. Here I use the very handy transformations module from Christoph Gohlke at the University of California. Importantly, when converting to quaternions, don’t forget to normalize the quaternions to unit length.
from abr_control.arms import ur5 as arm
from abr_control.interfaces import VREP
from abr_control.utils import transformations
robot_config = arm.Config()
interface = VREP(robot_config)
interface.connect()
feedback = interface.get_feedback()
# get the end-effector orientation matrix
R_e = robot_config.R('EE', q=feedback['q'])
# calculate the end-effector unit quaternion
q_e = transformations.unit_vector(
transformations.quaternion_from_matrix(R_e))
# get the target information from VREP
target = np.hstack([
interface.get_xyz('target'),
interface.get_orientation('target')])
# calculate the target orientation rotation matrix
R_d = transformations.euler_matrix(
target[3], target[4], target[5], axes='rxyz')[:3, :3]
# calculate the target orientation unit quaternion
q_d = transformations.unit_vector(
transformations.quaternion_from_euler(
target[3], target[4], target[5],
axes='rxyz')) # converting angles from 'rotating xyz'
Generating the orientation error
I implemented 4 different methods for calculating the orientation error, from (Caccavale et al, 1998), (Yuan, 1988) and (Nakinishi et al, 2008), and then one based off some code I found on Stack Overflow. I’ll describe each below, and then we’ll look at the results of applying them in VREP.
Method 1 – Based on code from StackOverflow
Given two orientation quaternion 
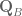
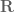

To isolate 
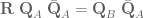
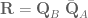
Great! Now we know how to calculate the rotation needed to get from the current orientation to the target orientation. Next, we have to get from
For control purposes, the last three elements of the quaternion define the roll, pitch, and yaw rotational errors…
So you can just take the vector part of the quaternion
# calculate the rotation between current and target orientations
q_r = transformations.quaternion_multiply(
q_target, transformations.quaternion_conjugate(q_e))
# convert rotation quaternion to Euler angle forces
u_task[3:] = ko * q_r[1:] * np.sign(q_r[0])
NOTE: You will run into issues when the angle 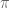
q_r[1:] * np.sign(q_r[0]). This will make sure that you always rotate along a trajectory < 180 degrees towards the target angle. The reason that this crops up is because there are multiple different quaternions that can represent the same orientation.
The following figure shows the arm being directed from and to the same orientations, where the one on the left takes the long way around, and the one on the right multiplies by the sign of the scalar component of the
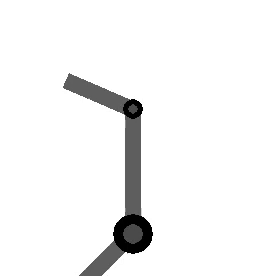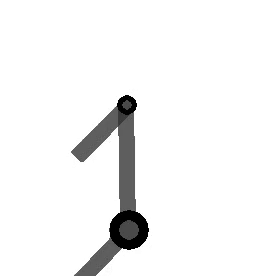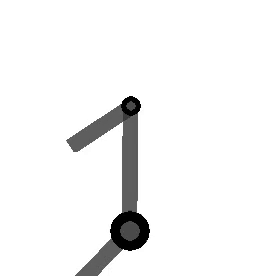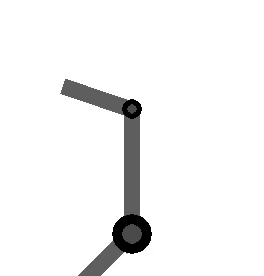
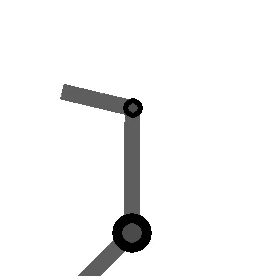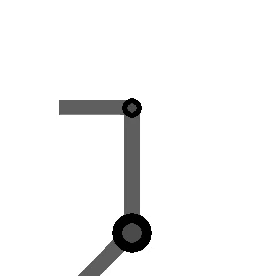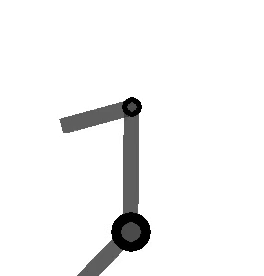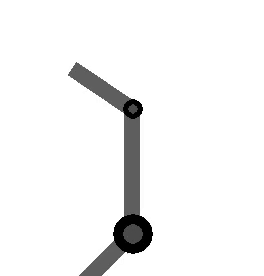
Method 2 – Quaternion feedback from Resolved-acceleration control of robot manipulators: A critical review with experiments (Caccavale et al, 1998)
In section IV, equation (34) of this paper they specify the orientation error to be calculated as
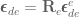
where 


To implement this is pretty straight forward using the transforms.py module to handle the representation conversions:
# From (Caccavale et al, 1997) # Section IV - Quaternion feedback R_ed = np.dot(R_e.T, R_d) # eq 24 q_ed = transformations.quaternion_from_matrix(R_ed) q_ed = transformations.unit_vector(q_ed) u_task[3:] = -np.dot(R_e, q_ed[1:]) # eq 34
Method 3 – Angle/axis feedback from Resolved-acceleration control of robot manipulators: A critical review with experiments (Caccavale et al, 1998)
In section V of the paper, they present an angle / axis feedback algorithm, which overcomes the singularity issues that classic Euler angle methods suffer from. The algorithm defines the orientation error in equation (45) to be calculated
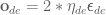
where 


Where 
# From (Caccavale et al, 1997) # Section V - Angle/axis feedback R_de = np.dot(R_d, R_e.T) # eq 44 q_ed = transformations.quaternion_from_matrix(R_de) q_ed = transformations.unit_vector(q_ed) u_task[3:] = -2 * q_ed[0] * q_ed[1:] # eq 45
From playing around with this briefly, it seems like this method also works. The authors note in the discussion that it may “suffer in the case of large orientation errors”, but I wasn’t able to elicit poor behaviour when playing around with it in VREP. The other downside they mention is that the computational burden is heavier with this method than with quaternion feedback.
Method 4 – From Closed-loop manipulater control using quaternion feedback (Yuan, 1988) and Operational space control: A theoretical and empirical comparison (Nakanishi et al, 2008)
This was the one method that I wasn’t able to get implemented / working properly. Originally presented in (Yuan, 1988), and then modified for representing the angular velocity in world and not local coordinates in (Nakanishi et al, 2008), the equation for generating error (Nakanishi eq 72):

where 


![\left[ \begin{array}{ccc} 0 & -\textbf{x}[2] & \textbf{x}[1] \\ \textbf{x}[2] & 0 & -\textbf{x}[0] \\ -\textbf{x}[1] & \textbf{x}[0] & 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+0+%26+-%5Ctextbf%7Bx%7D%5B2%5D+%26+%5Ctextbf%7Bx%7D%5B1%5D+%5C%5C+%5Ctextbf%7Bx%7D%5B2%5D+%26+0+%26+-%5Ctextbf%7Bx%7D%5B0%5D+%5C%5C+-%5Ctextbf%7Bx%7D%5B1%5D+%26+%5Ctextbf%7Bx%7D%5B0%5D+%26+0+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=555555&s=0&c=20201002)
My code for this implementation looks like:
S = np.array([
[0.0, -q_d[2], q_d[1]],
[q_d[2], 0.0, -q_d[0]],
[-q_d[1], q_d[0], 0.0]])
u_task[3:] = -(q_d[0] * q_e[1:] - q_e[0] * q_d[1:] +
np.dot(S, q_e[1:]))
If you understand why this isn’t working, if you can provide a working code example in the comments I would be very grateful.
Generating the full orientation control signal
The above steps generate the task-space control signal, and from here I’m just using standard operational space control methods to take u_task and transform it into joint torques to send out to the arm. With possibly the caveat that I’m accounting for velocity in joint-space, not task space. Generating the full control signal looks like:
# which dim to control of [x, y, z, alpha, beta, gamma]
ctrlr_dof = np.array([False, False, False, True, True, True])
feedback = interface.get_feedback()
# get the end-effector orientation matrix
R_e = robot_config.R('EE', q=feedback['q'])
# calculate the end-effector unit quaternion
q_e = transformations.unit_vector(
transformations.quaternion_from_matrix(R_e))
# get the target information from VREP
target = np.hstack([
interface.get_xyz('target'),
interface.get_orientation('target')])
# calculate the target orientation rotation matrix
R_d = transformations.euler_matrix(
target[3], target[4], target[5], axes='rxyz')[:3, :3]
# calculate the target orientation unit quaternion
q_d = transformations.unit_vector(
transformations.quaternion_from_euler(
target[3], target[4], target[5],
axes='rxyz')) # converting angles from 'rotating xyz'
# calculate the Jacobian for the end effectora
# and isolate relevate dimensions
J = robot_config.J('EE', q=feedback['q'])[ctrlr_dof]
# calculate the inertia matrix in task space
M = robot_config.M(q=feedback['q'])
# calculate the inertia matrix in task space
M_inv = np.linalg.inv(M)
Mx_inv = np.dot(J, np.dot(M_inv, J.T))
if np.linalg.det(Mx_inv) != 0:
# do the linalg inverse if matrix is non-singular
# because it's faster and more accurate
Mx = np.linalg.inv(Mx_inv)
else:
# using the rcond to set singular values < thresh to 0
# singular values < (rcond * max(singular_values)) set to 0
Mx = np.linalg.pinv(Mx_inv, rcond=.005)
u_task = np.zeros(6) # [x, y, z, alpha, beta, gamma]
# generate orientation error
# CODE FROM ONE OF ABOVE METHODS HERE
# remove uncontrolled dimensions from u_task
u_task = u_task[ctrlr_dof]
# transform from operational space to torques and
# add in velocity and gravity compensation in joint space
u = (np.dot(J.T, np.dot(Mx, u_task)) -
kv * np.dot(M, feedback['dq']) -
robot_config.g(q=feedback['q']))
# apply the control signal, step the sim forward
interface.send_forces(u)
The control script in full context is available up on my GitHub along with the corresponding VREP scene. If you download and run both (and have the ABR Control repo installed), then you can generate fun videos like the following:
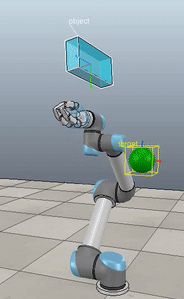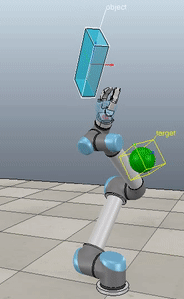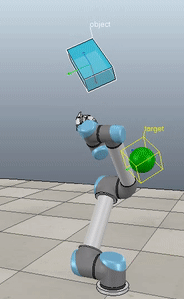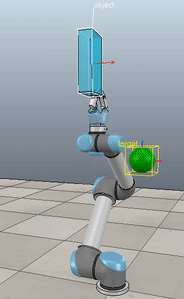
Method 1 – Stack overflow code 
Method 2 – Caccavale quaternion
Method 3 – Caccavale angle/axis 
Method 4 – Yuan / Nakanishi
Here, the green ball is the target, and the end-effector is being controlled to match the orientation of the ball. The blue box is just a visualization aid for displaying the orientation of the end-effector. And that hand is on there just from another project I was working on then forgot to remove but already made the videos so here we are. It’s set to not affect the dynamics so don’t worry. The target changes orientation once a second. The orientation gain for these trials is ko=200 and kv=np.sqrt(600).
The first three methods all perform relatively similarly to each other, although method 3 seems to be a bit faster to converge to the target orientation after the first movement. But it’s pretty clear something is terribly wrong with the implementation of the Yuan algorithm in method 4; brownie points for whoever figures out what!
Controlling position and orientation
So you want to use force control to control both position and orientation, eh? You are truly reaching for the stars, and I applaud you. For the most part, this is pretty straight-forward. But there are a couple of gotchyas so I’ll explicitly go through the process here.
How many degrees-of-freedom (DOF) can be controlled?
If you recall from my article on Jacobians, there was a section on analysing the Jacobian. It comes down to two main points: 1) The Jacobian specifies which task-space DOF can be controlled. If there is a row of zeros, for example, the corresponding task-space DOF (i.e. 
For example, in a two joint planar arm, the 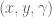
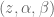

controlling 3 DOF 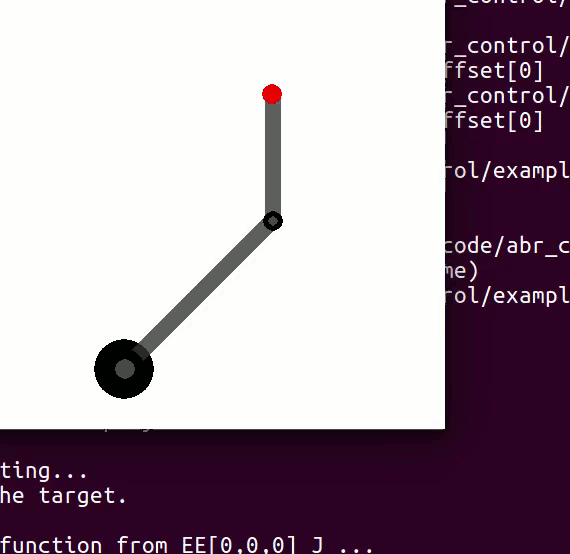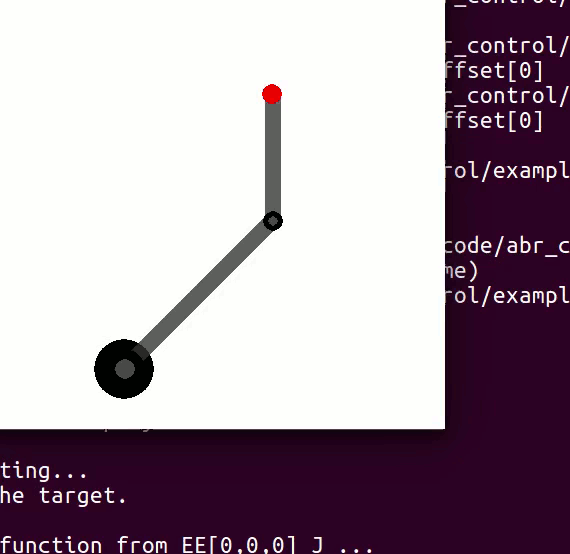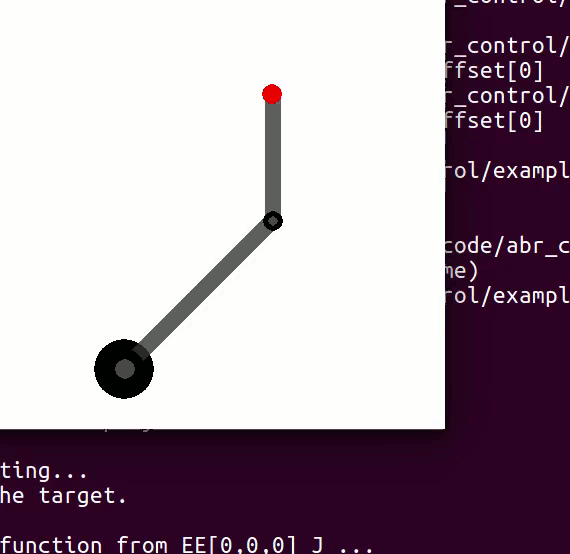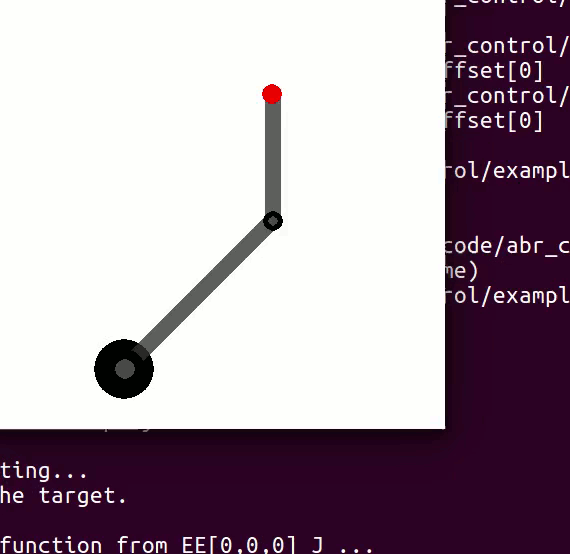
controlling 2 DOF
How to specify which DOF are being controlled?
Okay, so we don’t want to try to control too many DOF at once. Got it. Let’s say we know that our arm has 3 DOF, how do we choose which DOF to control? Simple: You remove the rows from you Jacobian and your control signal that correspond to task-space DOF you don’t want to control.
To implement this in code in a flexible way, I’ve chosen to specify an array with 6 boolean elements, set to True if you want to control the corresponding task space parameter and False if you don’t. For example, if you to control just the ctrl_dof = [True, True, True, False, False, False].
We then strip the Jacobian and task space control signal down to the relevant rows with J = robot_config.('EE', q)[ctrlr_dof] and u_task = (current - target)[ctrlr_dof]. This means that both current and target must be 6-dimensional vectors specifying the current and target
Generating a position + orientation control signal
The UR5 has 6 degrees of freedom, so we’re able to fully control the task space position and orientation. To do this, in the above script just ctrl_dof = np.array([True, True, True, True, True, True]), and there you go! In the following animations the gain values used were kp=300, ko=300, and kv=np.sqrt(kp+ko)*1.5. The full script can be found up on my GitHub.

Method 1 – Stack overflow code 
Method 2 – Caccavale quaternion
Method 3 – Caccavale angle/axis 
Method 4 – Yuan / Nakanishi
NOTE: Setting the gains properly for this task is pretty critical, and I did it just by trial and error until I got something that was decent for each. For a real comparison, better parameter tuning would have to be undertaken more rigorously.
NOTE: When implementing this minimal code example script I ran into a problem that was caused by the task-space inertia matrix calculation. It turns out that using np.linalg.pinv gives very different results than np.linalg.inv, and I did not realise this. I’m going to have to explore this more fully later, but basically heads up that you want to be using np.linalg.inv as much as possible. So you’ll notice in the above code I check the dimensionality of Mx_inv and first try to use np.linalg.inv before resorting to np.linalg.pinv.
NOTE: If you start playing around with controlling only one or two of the orientation angles, something to keep in mind: Because we’re using rotating axes, if you set up False, False, True then it’s not going to look like
In summary
So that’s that! Lots of caveats, notes, and more work to be done, but hopefully this will be a useful resource for any others embarking on the same journey. You can download the code, try it out, and play around with the gains and targets. Let me know below if you have any questions or enjoyed the post, or want to share any other resources on force control of task-space orientation.
And once again thanks to Yitao Ding for his helpful comments and corrections on the original version of this article.
