Alright, in my last post on RL we looked at egocentric learning and what that is. We also saw that both ego and allocentric learning have their strong points, and they compliment each other. So, some combination of these two approaches seems like a good idea. In this post we’re going to look at combining the output from these two kinds of learners and see the strengths of different weightings. Per usual, all the code from this post is up on my Github.
Combining allocentric and egocentric approaches
There are a few different ways that come to mind that we could combine these two learning styles. In each of these cases the overall setup is that we’re going to run two learning systems, one that is allocentric and one that is egocentric, combine their action value mappings for the current state in some way, and then decide which action to take based on their combined output. So here are several possible ways to combine the outputs:
- Only use allocentric
- Only use egocentric
- Average the mappings
- Dynamically change weights
There are, of course, many more ways to weight these systems, but these are some basic ones and they’re what we’re going to look at here.
For testing each of these these different setups we are going to run the mouse on a map for a set amount of time, measure the wins, accidental deaths, and intentional deaths, and then gather statistics (mean value and confidence intervals) across 10 trials.
A side note: The rate of exploration (epsilon value) starts out at .1 and is decreased by half every 100,000 simulation time step, so there are a number of jumps where you see the number of wins go up every 100,000, and that’s an artifact of the rate of exploration dropping (i.e. increasing your exploitation of what you already know about the world).
OK, we’re going to do this across 3 different maps, where the size and complexity increases with each map.
Map 1: the basic cliff map (which should look familiar):

Map 2: a middlesized map with several areas that are identical for the egocentric state:

and Map 3: a pretty large map with even more ambiguous areas:

Expectations
Now, what we expect from our learning systems is that the egocentric learner with have very few ‘suicide’ deaths, where it’s slow to learn that jumping off a cliff is a terrible idea. But on the flip side of that, since we’re going to set the gamma value of the egocentric learner to 0, (which means that it doesn’t incorporate anything other than the immediate reward into it’s learning, as discussed in the previous post), we expect that it will only rarely find the goal. Also, as the map gets larger, we expect that the goal will be found less and less, as it will have to randomly stumble around avoiding cliffs until it ends up in sight of the cheese.
From the allocentric learner we expect the death rate to be much higher than the egocentric learner, but we also expect the success rate to be significantly higher, as it will be able to identify how to move based on its current (x,y) position, rather than based on its immediate surroundings. As the map gets larger though, we expect the number of deaths to be larger, since there is no transfer of knowledge that jumping off a cliff in this position is as bad as jumping off a cliff in that position.
Alright! Let’s get to it!
Results
Only use allocentric
Not much to explain about this, the mouse is going to be learning Q-values where each state is its (x,y) position on the map. The bigger the map, the more deaths we expect this learner to have. So, here are the results:

Alright, so one of the most salient things in these plots is the stepping up of the number of wins at each of the 100,000 marks. Again, this is due to a transfer from exploration to exploitation of what’s already been learned as the epsilon value is decreased. And, also, as the map gets bigger, the number of wins takes longer to max out, but it’s pretty interesting how consistent the learning is (as seen by the very small confidence intervals on the runs) across trials given the random exploration.
Another point of note is that the number of deaths goes way up with the size of the map, as expected.
Only use egocentric
Again, this one is another straightforward case, the mouse is going to be learning Q-values where each state is its set of immediate neighbors (e.g. cliff to the right, cheese in front, empty cells left and behind). Here we expect that it will have a minimal number of deaths (not much more than a death for each of the situations it can encounter a cliff or cliffs in), and that the number of successes should be pretty low and very inconsistent, since it will be entirely based on randomly stumbling into a spot near the cheese while avoiding cliffs. Additionally, we expect the number of results to drop with increases in the size of the map. The results are below:

The results are as expected, lots of variation in the wins number, low suicide numbers, and the number of wins decreases with map sizes. Something that’s kind of interesting here is that you don’t see any real effects of the epsilon value as it decreases as you do in the egocentric case. I believe that this is because it achieves a balance of exploration that throws you off a cliff and exploration that moves you into the vicinity of the cheese. So it’s dying less when the exploration rate drops, but it also has less chance of reaching the cheese now. That’s my guess, at least. Alright! Next.
Average the allo and ego Q-values
Here we’re going to do the most basic combination of the allo and ego-centric learning possible. Both learners will run simultaneously, and generate a set of Q-values over the set of possible actions at each state, and we’ll average the output of both then choose the max Q-value to choose which action is taken. The hope here is that the ego-centric learner will very quickly learn not to jump off cliffs, and the allocentric learner will more slowly learn how to move in the map to get cheese. So we expect few deaths and more wins. Let’s look at the results:

Damn! So now we have the same (or at least very similar) win rate as the allocentric learner (awesome), and the same death rate as the egocentric learner (also awesome)! We have achieved some sort of super-human…or, super-mouse mouse. A super mouse. This is really cool, it tells us that these two systems really do compliment each other, and that it can be incredibly straightforward to implement a combination of the two.
Dynamic weighting
Here we’ll look at the results from a variation of an algorithm I’ve implemented based on this really interesting paper by Dr. Sakya Dasgupta et al where they got a lot of really neat results implemented on a little robot critter. We can’t quite use the algorithm as presented here for a couple of reasons.
In the paper, the authors design the algorithm for weighting the output from classical conditioning and operant conditioning systems. I’m taking these to be pretty close to analogous to an ego-centric learner (with no lookahead) and an allo-centric learner, respectively. The idea being that classical conditioning is based on immediate associations developed from rewards, and operant conditioning allows the longer-term associations to be formed. Specifically, in operant you learn to associate the conditioned stimulus with the unconditioned stimulus, which leads to a a conditioned response. The classic example being the dog salivating when hearing the bell, because it knows food is coming. Here the allocentric learner is doing a similar thing, using a look-ahead to start associating stimuli (in this case different states) with a reward or punishment. So, this could be a wildly inappropriate application of this algorithm, and the comparison definitely warrants further discussion.
The more immediate reason for varying the algorithm is because the output of their system is a continuous ‘left/right’ decision, and the output from the mouse here is a discrete ‘left/right/up/down’ decision. So the systems in the paper output a number from -1 to 1 that indicates which way to turn, and this is used in the update. So the algorithm needs to be changed up a little.
First, here’s the original algorithm:
weight_allo += eta * reward * [output_allo - filtered_output_allo] * output_ego
weight_ego += eta * reward * [output_ego - filtered_output_ego] * output_allo
where eta is the learning rate, reward is the immediate reward of the state you move into, output_ is the -1 to 1 value from the learners, and filtered_output_ is a low pass filtered version of the output. So the first part is standard, learning rate multiplied by the reward, and then the part inside the brackets is calculating a derivative of the output of the learners. This is again standard, did your learner change? If it did change and a reward was received, then increase the weight of that learner. The last term, which multiplies it all by the output from the other learner is for scaling.
And then normalize the weights relative to each other, and it isn’t explicitly stated in the paper, but also lower bound the weights at 0. The reason you need to do this lower bounding is that if you don’t, then when you use the weight as a gain on the learner output all of the Q-values are inverted! Not easy to recover from that.
The dynamic weighting equations that I’m using are:
weight_allo += eta * reward * dq_allo * output_ego
weight_ego += eta * reward * dq_ego * output_allo
and then lower bound at 0 and normalize.
There is still a lot in these equations that I’m unsure about (for example scaling by the output of the other learner instead of by the other weight, and how the signs of the reward, derivative, and other learner output all interact), but I’m going to leave delving into that for a future post, since this one is getting long already and I don’t have a full understanding of it yet. But! I have enough of an understanding to implement the above and run simulations! Here are the results:

I should note that the learning rate here for the weight equations is 5e-4. When you decrease this weight you get improved performance, but the best I’ve gotten is just reducing it to a point that it’s pretty much constantly using .5 for each. And that’s boring.
Alright, comparing to basic averaging here we notice that we have about the same performance for the small map, and then on the bigger maps significantly worse performance and also a lot more variability between runs. Basically what seems to happen is that the system quickly identifies that the allocentric learner should not have control at the beginning, because it keeps killing the mouse, and then it takes a lot longer to start handing control back over from the egocentric learner to the allocentric learner.
Conclusions
Alright, so that’s all! Bottom line is that allocentric and egocentric learning really work well together, and basic averaging of these gives great results. Whether this is the best means of combining them is unclear, however. This was just a really basic test of different combinations, and there is some really neat work looking at different ways to do it. It’s super fun to mess around with and there’s a ton of room for experimentation. In the code up on my Github, the code for weight learning can be found by searching for weight_learning. If anyone plays around and figures out a kick-ass dynamic weighting algorithm please pass it along!










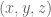 position of the end-effector, which we are interested in controlling, and the actual system state-space being something like the joint-angles or muscle-lengths. Configuration redundancy is the problem of more than one possible set of joint-angles putting the end-effector in the desired location. Often the number of potential solutions is incredibly large, think about the number of possible ways you can reach to an object. So how do you learn an appropriate trajectory for your joint angles during a reaching movement? That is the problem being addressed here.
position of the end-effector, which we are interested in controlling, and the actual system state-space being something like the joint-angles or muscle-lengths. Configuration redundancy is the problem of more than one possible set of joint-angles putting the end-effector in the desired location. Often the number of potential solutions is incredibly large, think about the number of possible ways you can reach to an object. So how do you learn an appropriate trajectory for your joint angles during a reaching movement? That is the problem being addressed here. , joint angles as
, joint angles as 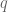 , and end effector positions as
, and end effector positions as  . Then to denote giving a desired end effector position and getting out a set of joint angles we write
. Then to denote giving a desired end effector position and getting out a set of joint angles we write 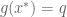 , where
, where  represents a target in end effector space.
represents a target in end effector space. . Additionally, we’re going to throw on some exploratory noise to the answer provided by the inverse model, so that the joint angles to move to at time
. Additionally, we’re going to throw on some exploratory noise to the answer provided by the inverse model, so that the joint angles to move to at time  are defined as
are defined as  , where
, where 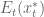 is the exploratory noise. When the system then moves to
is the exploratory noise. When the system then moves to  the end effector position,
the end effector position, 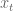 , is observed and the parameters of the inverse model,
, is observed and the parameters of the inverse model, 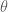 , are updated immediately.
, are updated immediately.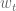 as it is taken in, based on deviation from the resting position of the arm (
as it is taken in, based on deviation from the resting position of the arm ( , where the entries to the matrix
, where the entries to the matrix  and vector
and vector  are chosen independently from a normal distribution with zero mean and variance
are chosen independently from a normal distribution with zero mean and variance  . To move, a set of small values is chosen from a normal distribution with variance significantly smaller than
. To move, a set of small values is chosen from a normal distribution with variance significantly smaller than  and
and 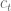 . A normalization term is also used to keep the overall deviation stable around the standard deviation
. A normalization term is also used to keep the overall deviation stable around the standard deviation 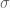 . And that’s how we get our slowly changing linear random noise function.
. And that’s how we get our slowly changing linear random noise function. , intuited as following the standard
, intuited as following the standard 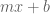 definition of a line, but moving into multiple dimensions.
definition of a line, but moving into multiple dimensions.  is our linear transformation of the input for model
is our linear transformation of the input for model 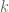 , and
, and  is the offset.
is the offset.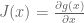 of the inverse estimate. In other words, we look at how the approximation of the function is changing as we move in this
of the inverse estimate. In other words, we look at how the approximation of the function is changing as we move in this  by reducing the weighted square error:
by reducing the weighted square error:  . With this error, a standard gradient descent method is used to update the slopes and offsets of the dimensions of the linear models:
. With this error, a standard gradient descent method is used to update the slopes and offsets of the dimensions of the linear models: ,
, is the learning rate.
is the learning rate.






