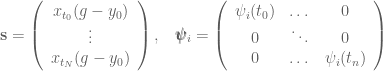Edit: Previously I posted this blog post on incorporating obstacle avoidance, but after a recent comment on the code I started going through it again and found a whole bunch of issues. Enough so that I’ve recoded things and I’m going to repost it now with working examples and a description of the changes I made to get it going. The edited sections will be separated out with these nice horizontal lines. If you’re just looking for the example code, you can find it up on my pydmps repo, here.
Alright. Previously I’d mentioned in one of these posts that DMPs are awesome for generalization and extension, and one of the ways that they can be extended is by incorporating obstacle avoidance dynamics. Recently I wanted to implement these dynamics, and after a bit of finagling I got it working, and so that’s going to be the subject of this post.
There are a few papers that talk about this, but the one we’re going to use is Biologically-inspired dynamical systems for movement generation: automatic real-time goal adaptation and obstacle avoidance by Hoffmann and others from Stefan Schaal’s lab. This is actually the second paper talking about obstacle avoidance and DMPs, and this is a good chance to stress one of the most important rules of implementing algorithms discussed in papers: collect at least 2-3 papers detailing the algorithm (if possible) before attempting to implement it. There are several reasons for this, the first and most important is that there are likely some typos in the equations of one paper, by comparing across a few papers it’s easier to identify trickier parts, after which thinking through what the correct form should be is usually straightforward. Secondly, often equations are updated with simplified notation or dynamics in later papers, and you can save yourself a lot of headaches in trying to understand them just by reading a later iteration. I recklessly disregarded this advice and started implementation using a single, earlier paper which had a few key typos in the equations and spent a lot of time tracking down the problem. This is just a peril inherent in any paper that doesn’t provide tested code, which is almost all, sadface.
OK, now on to the dynamics. Fortunately, I can just reference the previous posts on DMPs here and don’t have to spend any time discussing how we arrive at the DMP dynamics (for a 2D system):

where 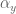
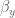
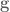
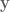

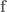
As mentioned, DMPs are awesome because now to add obstacle avoidance all we have to do is add another term
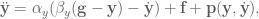
where 
Obstacle avoidance dynamics
It turns out that there is a paper by Fajen and Warren that details an algorithm that mimics human obstacle avoidance. The idea is that you calculate the angle between your current velocity and the direction to the obstacle, and then turn away from the obstacle. The angle between current velocity and direction to the obstacle is referred to as the steering angle, denoted 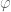

So, given some 

If we’re on track to hit the object (i.e.

where 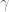

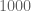

Edit: OK this all sounds great, but quickly you run into issues here. The first is how do we calculate 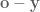
np.arccos to get the angle from that. There is a big problem with this here, however, that’s kind of subtle: You will never get a negative angle when you calculate this, which, of course. That’s not how np.arccos works, but it is still what we need so we will be able to tell if we should be turning left or right to avoid this object!
So we need to use a different way of calculating the angle, one that tells us if the object is in a + or – angle relative to the way we’re headed. To calculate an angle that will give us + or -, we’re going to use the np.arctan2 function.
We want to center things around the way we’re headed, so first we calculate the angle of the direction vector, R_dy to rotate the vector describing the direction of the object. This shifts things around so that if we’re moving straight towards the object it’s at 0 degrees, if we’re headed directly away from it, it’s at 180 degrees, etc. Once we have that vector, nooowwww we can find the angle of the direction of the object and that’s what we’re going to use for phi. Huzzah!
# get the angle we're heading in
phi_dy = -np.arctan2(dy[1], dy[0])
R_dy = np.array([[np.cos(phi_dy), -np.sin(phi_dy)],
[np.sin(phi_dy), np.cos(phi_dy)]])
# calculate vector to object relative to body
obj_vec = obstacle - y
# rotate it by the direction we're going
obj_vec = np.dot(R_dy, obj_vec)
# calculate the angle of obj relative to the direction we're going
phi = np.arctan2(obj_vec[1], obj_vec[0])
This
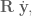
where 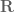
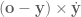


So that whole thing takes into account absolute distance to object along each axis, but that’s not quite enough. We also need to throw in
OK so all in all this whole term is written out
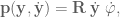
and that’s what we add in to the system acceleration. And now our DMP can avoid obstacles! How cool is that?
Super compact, straight-forward to add, here’s the code:
Edit: OK, so not suuuper compact. I’ve also added in another couple checks. The big one is “Is this obstacle between us and the target or not?”. So I calculate the Euclidean distance to the goal and the obstacle, and if the obstacle is further away then the goal, set the avoidance signal to zero (performed at the end of the if)! This took care of a few weird errors where you would get a big deviation in the trajectory if it saw an obstacle past the goal, because it was planning on avoiding it, but then was pulled back in to the goal before the obstacle anyways so it was a pointless exercise. The other check added in is just to make sure you only add in obstacle avoidance if the system is actually moving. Finally, I also changed the 
def avoid_obstacles(y, dy, goal):
p = np.zeros(2)
for obstacle in obstacles:
# based on (Hoffmann, 2009)
# if we're moving
if np.linalg.norm(dy) > 1e-5:
# get the angle we're heading in
phi_dy = -np.arctan2(dy[1], dy[0])
R_dy = np.array([[np.cos(phi_dy), -np.sin(phi_dy)],
[np.sin(phi_dy), np.cos(phi_dy)]])
# calculate vector to object relative to body
obj_vec = obstacle - y
# rotate it by the direction we're going
obj_vec = np.dot(R_dy, obj_vec)
# calculate the angle of obj relative to the direction we're going
phi = np.arctan2(obj_vec[1], obj_vec[0])
dphi = gamma * phi * np.exp(-beta * abs(phi))
R = np.dot(R_halfpi, np.outer(obstacle - y, dy))
pval = -np.nan_to_num(np.dot(R, dy) * dphi)
# check to see if the distance to the obstacle is further than
# the distance to the target, if it is, ignore the obstacle
if np.linalg.norm(obj_vec) > np.linalg.norm(goal - y):
pval = 0
p += pval
return p
And that’s it! Just add this method in to your DMP system and call avoid_obstacles at every timestep, and add it in to your DMP acceleration.
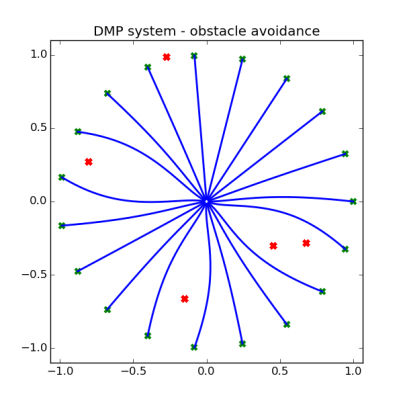
You hopefully noticed in the code that this is set up for multiple obstacles, and that all that that entailed was simply adding the p value generated by each individual obstacle. It’s super easy! Here’s a very basic graphic showing how the DMP system can avoid obstacles:

So here there’s just a basic attractor system (DMP without a forcing function) trying to move from the center position to 8 targets around the unit circle (which are highlighted in red), and there are 4 obstacles that I’ve thrown onto the field (black x’s). As you can see, the system successfully steers way clear of the obstacles while moving towards the target!
We must all use this power wisely.
Edit: Making the power yours is now easier than ever! You can check out this code at my pydmps GitHub repo. Clone the repo and after you python setup.py develop, change directories into the examples folder and run the avoid_obstacles.py file. It will randomly generate 5 targets in the environment and perform 20 movements, giving you something looking like this:
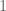 to
to 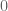 and then we were all done. In the rhythmic case we want our system to repeat indefinitely, so we need a reliable way of continuously activating the basis functions in the same order. One function that may come to mind that reliably repeats is the cosine function. But how to use the cosine function, exactly?
and then we were all done. In the rhythmic case we want our system to repeat indefinitely, so we need a reliable way of continuously activating the basis functions in the same order. One function that may come to mind that reliably repeats is the cosine function. But how to use the cosine function, exactly?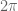 , and we’ll set the canonical system to be ever increasing linearly. Then we’ll use the difference between the canonical system state and each of the center points as the value we pass in to our cosine function. Because the cosine function repeats at
, and we’ll set the canonical system to be ever increasing linearly. Then we’ll use the difference between the canonical system state and each of the center points as the value we pass in to our cosine function. Because the cosine function repeats at 
 is the basis function center point, and
is the basis function center point, and 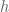 is a gain term controlling the variance of the Gaussian. And here’s a picture of the activations of three basis functions with centers spread out evenly between
is a gain term controlling the variance of the Gaussian. And here’s a picture of the activations of three basis functions with centers spread out evenly between 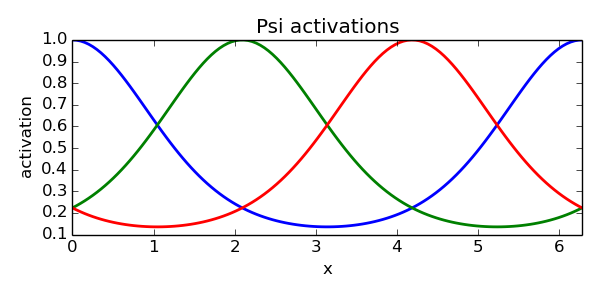




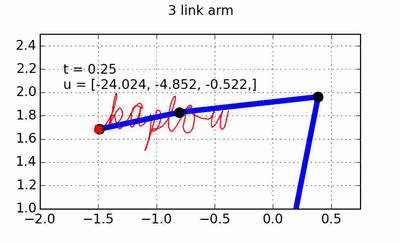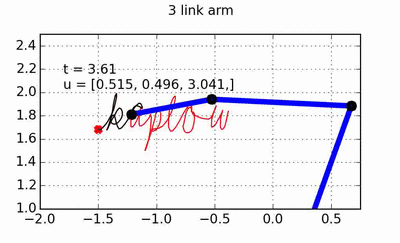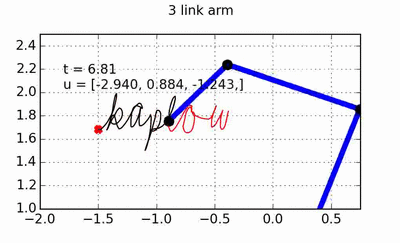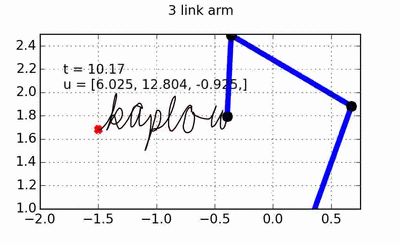
 trajectory of the hand, and the OSC will take care of turning the desired hand forces into torques that can be applied to the arm. All of the code used to generate the animations throughout this post can of course be found
trajectory of the hand, and the OSC will take care of turning the desired hand forces into torques that can be applied to the arm. All of the code used to generate the animations throughout this post can of course be found 
 is the state of the DMP system,
is the state of the DMP system,  is the state of the plant, and
is the state of the plant, and 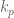 and is the position error gain term.
and is the position error gain term.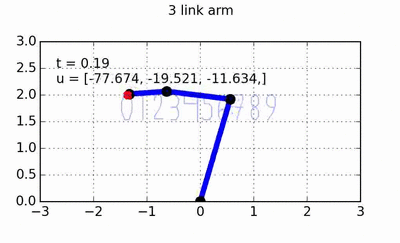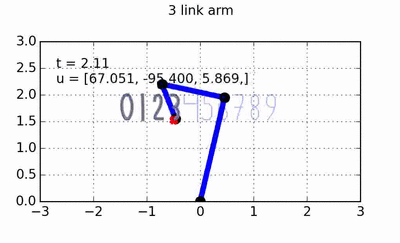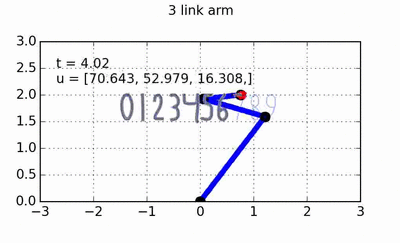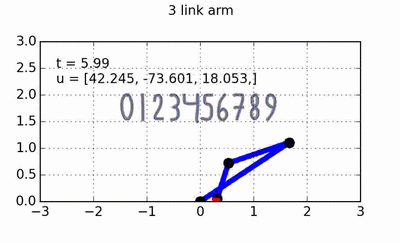
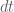 by a new term:
by a new term: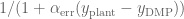 .
.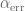 on the difference between the plant and DMP states.
on the difference between the plant and DMP states.




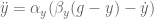 ,
, is the goal, and
is the goal, and 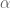 and
and  .
.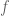 such that you get the desire behaviour is a non-trivial question. The crux of the DMP framework is an additional nonlinear system used to define the forcing function
such that you get the desire behaviour is a non-trivial question. The crux of the DMP framework is an additional nonlinear system used to define the forcing function 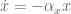 .
.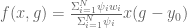 ,
, is the initial position of the system,
is the initial position of the system,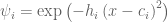 ,
,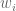 is a weighting for a given basis function
is a weighting for a given basis function 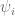 . You may recognize that the
. You may recognize that the 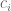 , where
, where  is the variance. So our forcing function is a set of Gaussians that are ‘activated’ as the canonical system
is the variance. So our forcing function is a set of Gaussians that are ‘activated’ as the canonical system 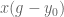 term, which is both a ‘diminishing’ and spatial scaling term.
term, which is both a ‘diminishing’ and spatial scaling term.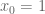 , and goes to 0 as time goes to infinity. For right now, let’s pretend that
, and goes to 0 as time goes to infinity. For right now, let’s pretend that 
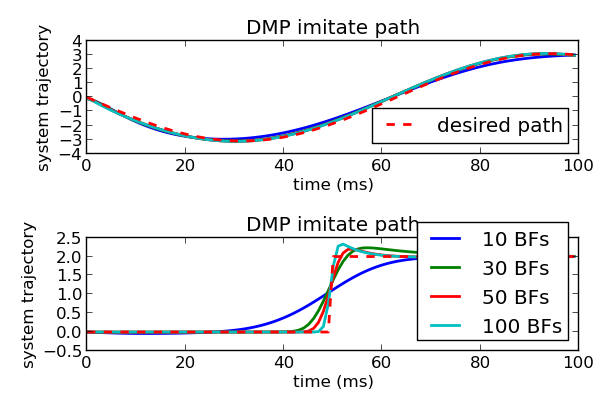
 term of the forcing function handles, by scaling the activation of each of these basis functions to be relative to the distance to the target, causing the system to cover more or less distance. For example, let’s say that we have a set of discrete DMPs set up to follow a given trajectory:
term of the forcing function handles, by scaling the activation of each of these basis functions to be relative to the distance to the target, causing the system to cover more or less distance. For example, let’s say that we have a set of discrete DMPs set up to follow a given trajectory:





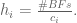
 is equal to the number of basis functions divided by the center of that basis function. When we do this, we can now generate centers for our basis functions that are well spaced out:
is equal to the number of basis functions divided by the center of that basis function. When we do this, we can now generate centers for our basis functions that are well spaced out:
 , our temporal scaling term. Given that our system dynamics are:
, our temporal scaling term. Given that our system dynamics are: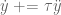 ,
, ,
, ,
,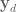 (where bold denotes a vector, in this case the time series of desired points in the trajectory), and differentiate it twice to get the accelerations:
(where bold denotes a vector, in this case the time series of desired points in the trajectory), and differentiate it twice to get the accelerations: .
.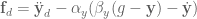 .
.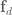 . In locally weighted regression sets up to minimize:
. In locally weighted regression sets up to minimize: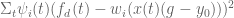
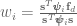 ,
,